Stratégie RSI basée sur l'amélioration des probabilités
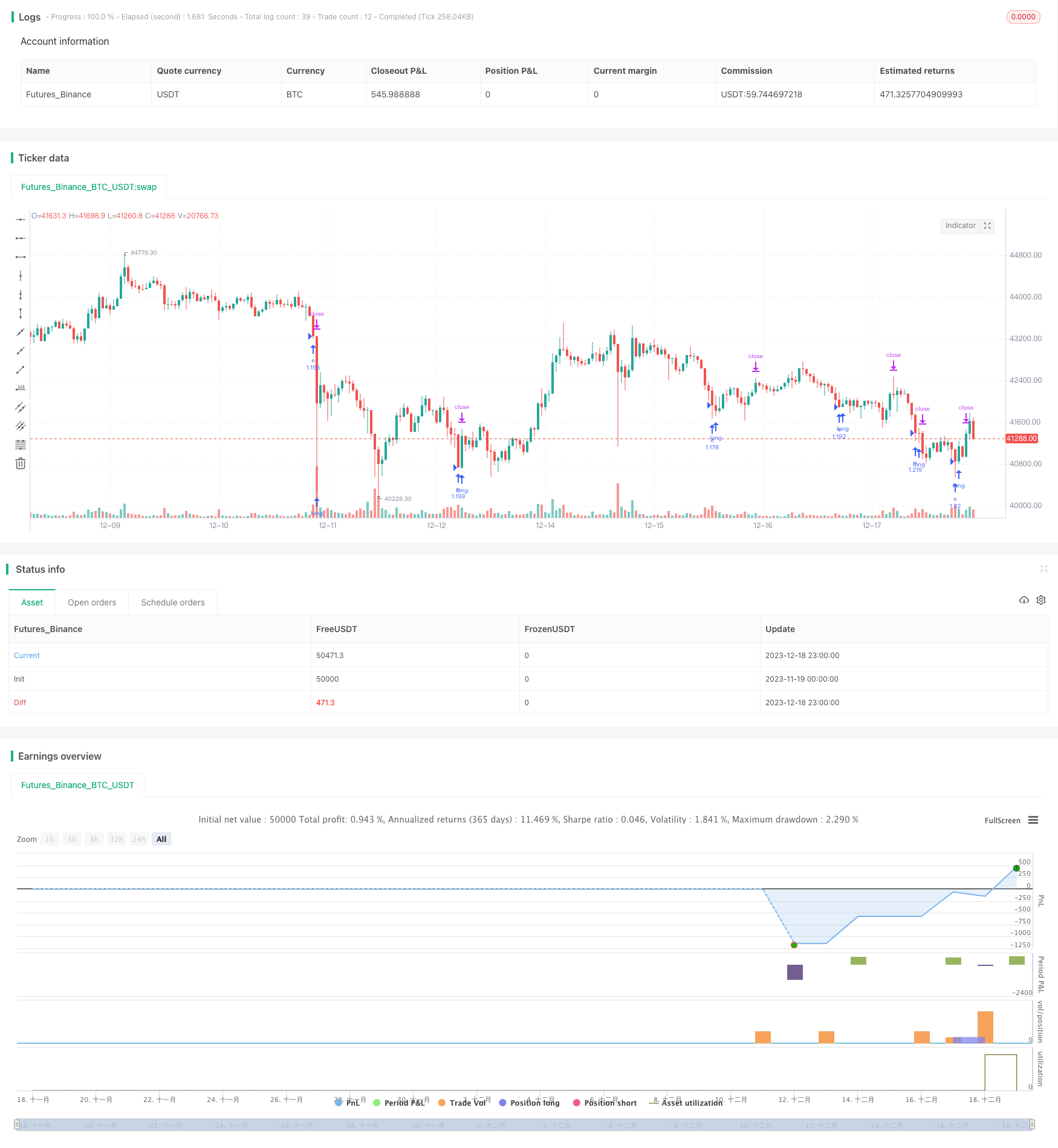
Aperçu
Cette stratégie est une simple stratégie de “ juste faire plus ” qui utilise le RSI pour juger de la sur-achat et de la sur-vente. Nous l’avons améliorée en ajoutant un stop-loss et en intégrant un module de probabilité pour augmenter la probabilité d’ouvrir une position uniquement si la probabilité d’une transaction rentable a été supérieure ou égale à 51% au cours de la période la plus récente.
Principe de stratégie
La stratégie utilise le RSI pour juger si le marché est en sur-achat ou en sur-vente. Plus précisément, nous faisons plus lorsque le RSI dépasse la limite inférieure de la zone de survente définie; et plus lorsque la limite supérieure de la zone de survente définie sur le RSI est en position de plafonnement. De plus, nous avons défini un taux de stop loss stop loss.
La clé est que nous avons intégré un module de jugement de probabilité. Ce module calcule le pourcentage de plus de transactions ou de pertes au cours de la période la plus récente (par paramètre lookback). La probabilité d’une transaction récente rentable est supérieure ou égale à 51%. Cela réduit considérablement les transactions potentiellement déficitaires.
Analyse des avantages
Il s’agit d’une stratégie RSI à probabilité accrue qui présente les avantages suivants par rapport à une stratégie RSI ordinaire:
- Ajout d’un paramètre Stop Loss pour limiter les pertes individuelles et bloquer les gains
- Module de probabilité intégré pour éviter les marchés à faible probabilité de profit vrf
- Les paramètres du module de probabilité sont réglables et optimisés pour différents environnements de marché
- Il suffit de faire plus de mécanismes simples, faciles à comprendre et à mettre en œuvre.
Analyse des risques
Cette stratégie comporte aussi des risques:
- Il n’y a pas d’argent à gagner en faisant trop.
- Un mauvais calcul du module de probabilité peut vous faire rater une opportunité.
- La combinaison optimale de paramètres n’a pas été déterminée et les performances varient considérablement selon les environnements de marché.
- Les réglages de stop loss sont trop laxistes et les pertes individuelles peuvent être encore plus importantes.
La réponse:
- Un mécanisme de couverture peut être envisagé
- Optimiser les paramètres du module de probabilité pour réduire la probabilité d’erreur de jugement
- Paramètres d’optimisation dynamique utilisant une méthode d’apprentissage automatique
- Définir des niveaux de stop plus conservateurs pour réduire les marges de perte
Direction d’optimisation
Cette stratégie peut être optimisée dans les domaines suivants:
- Ajout d’un module de courtage permettant des transactions bidirectionnelles
- Définition des paramètres d’optimisation dynamique à l’aide de méthodes d’apprentissage automatique
- Essayez d’utiliser d’autres indicateurs pour juger de la survente
- Optimiser les stratégies de stop-loss pour optimiser le ratio profit/perte
- Le filtrage des signaux, combiné à d’autres facteurs, améliore la probabilité
Résumer
Cette stratégie est une stratégie RSI simple, avec une amélioration du module de jugement de probabilité intégré. Par rapport à la stratégie RSI ordinaire, il est possible de filtrer une partie des transactions à perte et d’optimiser le retrait global et le ratio de gain et de perte.
/*backtest
start: 2023-11-19 00:00:00
end: 2023-12-19 00:00:00
period: 1h
basePeriod: 15m
exchanges: [{"eid":"Futures_Binance","currency":"BTC_USDT"}]
*/
// This source code is subject to the terms of the Mozilla Public License 2.0 at https://mozilla.org/MPL/2.0/
// © thequantscience
//@version=5
strategy("Reinforced RSI",
overlay = true,
default_qty_type = strategy.percent_of_equity,
default_qty_value = 100,
pyramiding = 1,
currency = currency.EUR,
initial_capital = 1000,
commission_type = strategy.commission.percent,
commission_value = 0.07)
lenght_rsi = input.int(defval = 14, minval = 1, title = "RSI lenght: ")
rsi = ta.rsi(close, length = lenght_rsi)
rsi_value_check_entry = input.int(defval = 35, minval = 1, title = "Oversold: ")
rsi_value_check_exit = input.int(defval = 75, minval = 1, title = "Overbought: ")
trigger = ta.crossunder(rsi, rsi_value_check_entry)
exit = ta.crossover(rsi, rsi_value_check_exit)
entry_condition = trigger
TPcondition_exit = exit
look = input.int(defval = 30, minval = 0, maxval = 500, title = "Lookback period: ")
Probabilities(lookback) =>
isActiveLong = false
isActiveLong := nz(isActiveLong[1], false)
isSellLong = false
isSellLong := nz(isSellLong[1], false)
int positive_results = 0
int negative_results = 0
float positive_percentage_probabilities = 0
float negative_percentage_probabilities = 0
LONG = not isActiveLong and entry_condition == true
CLOSE_LONG_TP = not isSellLong and TPcondition_exit == true
p = ta.valuewhen(LONG, close, 0)
p2 = ta.valuewhen(CLOSE_LONG_TP, close, 0)
for i = 1 to lookback
if (LONG[i])
isActiveLong := true
isSellLong := false
if (CLOSE_LONG_TP[i])
isActiveLong := false
isSellLong := true
if p[i] > p2[i]
positive_results += 1
else
negative_results -= 1
positive_relative_probabilities = positive_results / lookback
negative_relative_probabilities = negative_results / lookback
positive_percentage_probabilities := positive_relative_probabilities * 100
negative_percentage_probabilities := negative_relative_probabilities * 100
positive_percentage_probabilities
probabilities = Probabilities(look)
lots = strategy.equity/close
var float e = 0
var float c = 0
tp = input.float(defval = 1.00, minval = 0, title = "Take profit: ")
sl = input.float(defval = 1.00, minval = 0, title = "Stop loss: ")
if trigger==true and strategy.opentrades==0 and probabilities >= 51
e := close
strategy.entry(id = "e", direction = strategy.long, qty = lots, limit = e)
takeprofit = e + ((e * tp)/100)
stoploss = e - ((e * sl)/100)
if exit==true
c := close
strategy.exit(id = "c", from_entry = "e", limit = c)
if takeprofit and stoploss
strategy.exit(id = "c", from_entry = "e", stop = stoploss, limit = takeprofit)