kNN 기반 트렌드 추종 전략

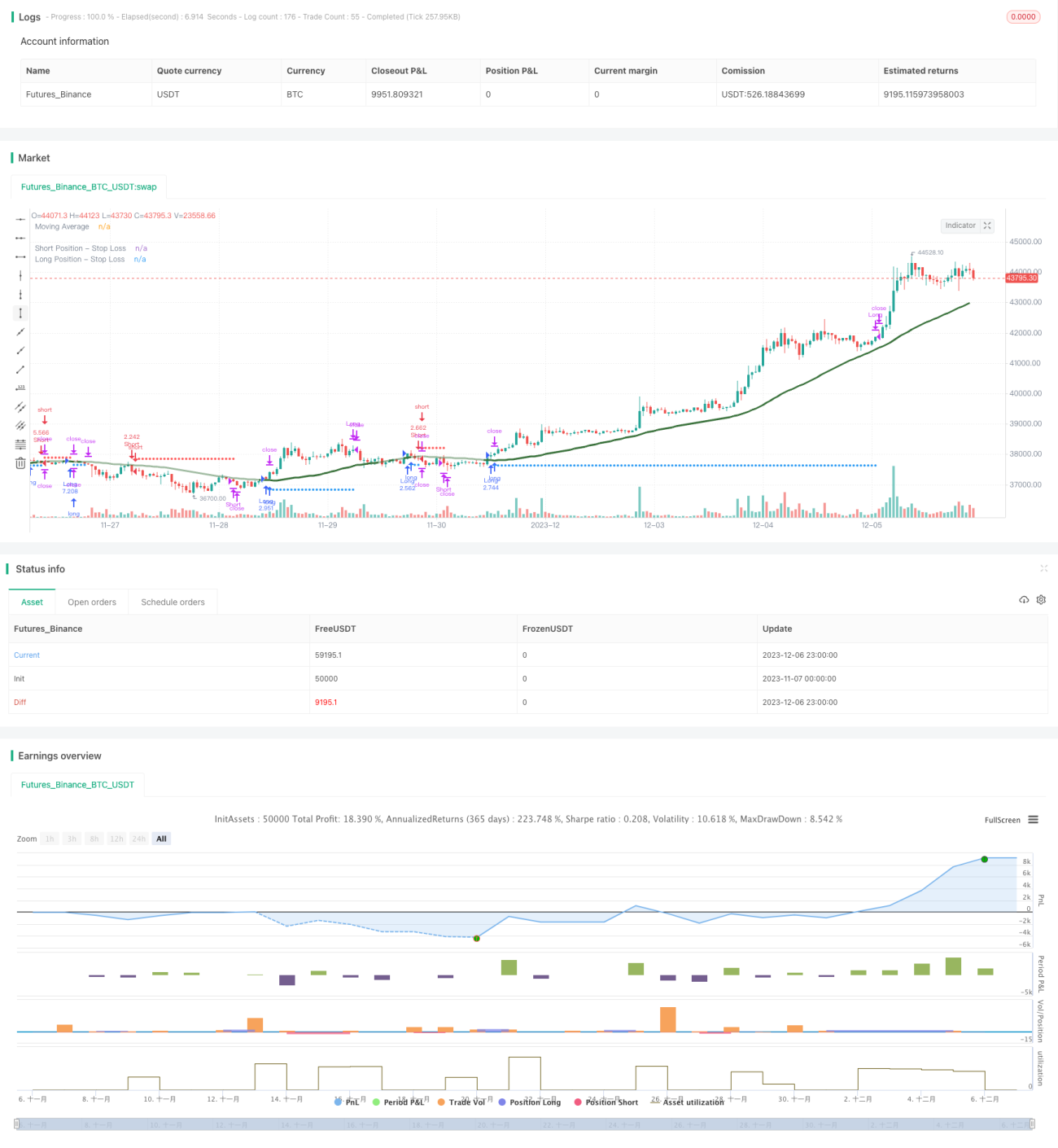
개요
이 전략은 k 근접 (kNN) 기계 학습 알고리즘을 사용하여 시장 추세를 예측하고, 예측 결과에 따라 긴 포지션과 빈 포지션 신호를 생성한다. 이 전략은 종합적으로 역사적 데이터, 기술 지표와 같은 여러 요소를 고려하고, kNN 모델 동력을 통해 시장 특성을 획득하고, 자동화 된 트렌드 추적 거래를 구현한다.
전략 원칙
-
훈련 데이터를 수집합니다. 역사적인 종식 가격, 거래량과 같은 시간 순서, RSI, CCI와 같은 기술 지표들을 수집합니다.
-
데이터 전처리: 지표값을 0-100의 범위로 정형화한다.
-
트레이닝 kNN 모델: 현재 kNN 모델의 두 가지 특징을 입력하고, 이들 특징 벡터와 역사 특징 벡터 사이의 유럽식 거리를 계산하고, 가장 가까운 k개의 역사 샘플의 거리를 선택하고, 이 k개의 샘플의 레이블 ((多頭 or 空頭) 분포 상황을 통계한다.
-
예측을 얻는다: k의 가장 가까운 이웃 샘플의 표기에 따라 현재 시장의 움직임을 예측한다. 예측이 다목적이라면, 긴 포지션 신호를 생성한다. 예측이 공백이라면, 빈 포지션 신호를 생성한다.
-
스톱로스, 포지션 제어, 이동 평균 등의 필터와 함께 거래한다.
전략적 이점
-
기계 학습 알고리즘을 사용하여 기술 형태를 자동으로 식별하고, 사람의 개입이 필요하지 않습니다.
-
다양한 기술 지표를 모델 특성으로 선택하여 실시간 최적화 전략을 적용할 수 있습니다.
-
통합된 스톱로스, 포지션 관리 등과 같은 엄격한 위험 제어 장치
-
시각화 상쇄선, 명확한 직관.
위험과 해결책
-
기계학습 예측에는 오류가 발생할 수 있다. 적절한 k값, 특징 벡터, 샘플링 시간 범위 등의 최적화 모델을 선택할 수 있다.
-
일방적인 거래는 잠재적인 위험이다. 코드에서 쌍방적인 거래를 추가하면 버그를 제거할 수 있다.
-
매개 변수 설정이 잘못되면 과도한 거래가 발생할 수 있다. 포지션 크기, 거래 빈도 등의 매개 변수들을 적절히 조정해야 한다.
최적화 방향
-
다양한 유형의 기술 지표를 kNN 입력 특성으로 테스트한다.
-
맨해튼 거리처럼 다른 거리 측정 방법을 시도해 보세요.
-
샘플 거리 또는 분류 질량을 사용하여 포지션 크기를 조정하십시오.
-
모델 트레이닝 세트를 추가하고, 테스트 세트를 분할하여, 스크롤 최적화를 구현한다.
요약하다
이 전략은 고전적인 kNN 알고리즘을 사용하여 시장 추세를 예측하고 예측 신호에 따라 추세를 따라 거래한다. 이 전략은 매개 변수를 조정할 수 있고, 위험을 제어할 수 있는 특징이 있으며, 사용자에게 효과적인 자동화 거래 프로그램을 제공할 수 있다. 사용자는 기술 지표 포트폴리오를 조정하거나, 모델 초 매개 변수를 최적화하는 등의 방법으로 전략 성능을 지속적으로 향상시킬 수 있다.
- 1